
























Coding is a necessary skill for Test Automation/SDET Engineers. However, it is important to write clean code that’s understandable and maintainable. In this blog post, I am going to explain What Is Clean Code, Why Have Clean Code, and provide 5 practical Tips For Writing Clean Code.
What Is Clean Code?
Clean code is code from a programming language that is easy to understand and painless to maintain. It’s easy to understand when the code is simple to follow. Painless to maintain means the code does not have unintended consequences when making an update. In addition, clean code allows multiple people to work on the project and follow the agreed guidelines.
With clean code, problems are straightforward to solve. Every problem solution begins with an algorithm. The algorithm is a plan translated into a design pattern. An effective design pattern is Page Object Model which identifies each web page as a class file.
The purpose of a class file is to encapsulate data and model behavior. Page Object Model encapsulates data by creating a repository for storing fields. It models behavior by defining actions for those stored fields. For example, the below images display a Google Search Page, 2 class files, and Google Results Page.
Within the Google Search Page, a user can search using the search text field and Google Search button. As a result, the Page Object Model illustrates clean code by separating its repository from its actions.
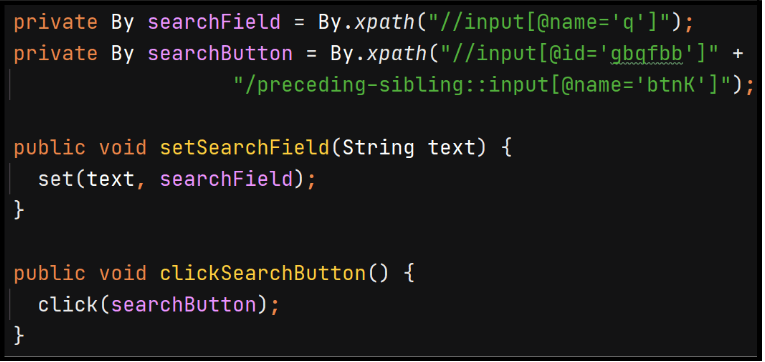
The 1st class file represents a Page Object Model design pattern.
- searchField and searchButton are encapsulated with a private access modifier
- setSearchField and clickSearchButton model a behavior performed on the web page. The method setSearchField() performs an action that allows a user to enter text. In this class file, the clickSearchButton() method carries out an action of clicking the Google Search button.

The 2nd class file serves as a Test file. It tests the Homepage of Google.
- First step calls the setSearchField() method and sets the search field to ACCELQ Automation Tool – Web and API Automation
- Second step calls the clickSearchButton() method and clicks the Google Search button
After clicking the Google Search button, the subsequent page shows results for ACCELQ:
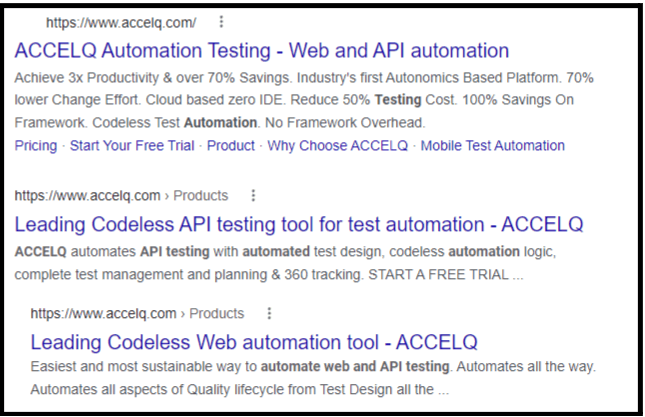
Why Have Clean Code?
One of the benefits to writing clean code is readability. Code readability is essential so it can make the process of extending and modifying the program clear. In addition, code readability reduces the possibility of confusion between the Test Automation/SDET team.
This helps because the project’s entire lifetime is rarely maintained by its original authors. The following is a list of questions to decide if the automation code is clean:
- How smooth will it be to maintain this code?
- Is this code complicated to update if the Application Under Test (AUT) changes?
- Can another engineer view this code and figure out the test script?
Tips For Writing Clean Code
Practically, writing clean code comes with time and effort. Although there are conventions, most references to clean code are subjective. The following is a list of accepted tips for writing clean code.
Use Descriptive Names
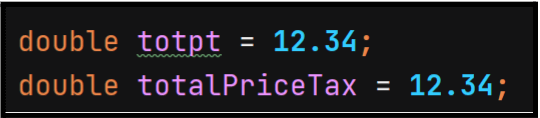
What does totpt stand for? Well, it is designed to be a variable for the total of price and tax. A valuable descriptive name for the same mention is totalPriceTax.
Code is much easier to read if we write out the complete name. There is not a reason to write the full name during declaration since IDE’s have a built-in code completion system. Variables should precisely define what data it holds. The name we define for classes and methods/functions should reveal its intent by fulfilling two objectives:
1. What it does in the program?
2. How will it be applied in the program?
A convention for writing constants, classes, and methods/functions includes
- Constants should be all uppercase, with words separated by underscores (_)
- Classes should be nouns
- Methods/Functions should be verbs
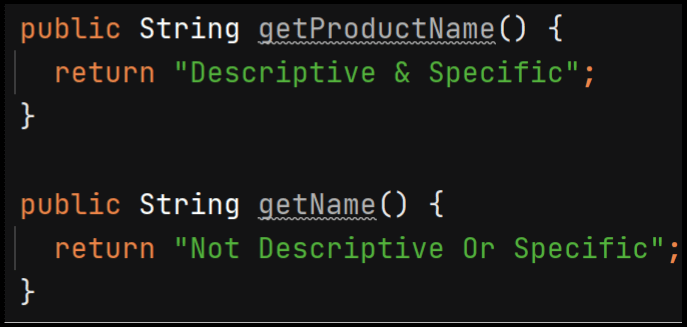
A descriptive name is detailed and specific. For example, an application has product names and customer names. A detail specific method/function name is getProductName() rather than getName(). The method getName() is not specific or detailed because it’s difficult to know if the code is retrieving products or customers.
Implement One Action For Each Method/Function
Clean code breaks down multiple automation steps into chunks. If a test script has numerous steps, then those steps are divided into pieces of code. A programming fundamental aims to make sure each method/function performs only one action.
As a result, a Test Automation/SDET Engineer would not incorporate various steps into one method/function. For instance, the Page Object Model for searching on Google should not combine entering text and clicking the Google Search button in one method/function.

If the method/function contains ‘And’ in its name, then probably best to cut the method/function, so they execute their own task. However, there is an exception for a convenient method/function. Convenience methods/functions achieve one goal but contain more than one step.
An example includes logging into an application. It completes only one action but involves entering a username, entering a password, and clicking the login button. All three steps can be joined to logIntoApplication() and/or isolated into individual steps.
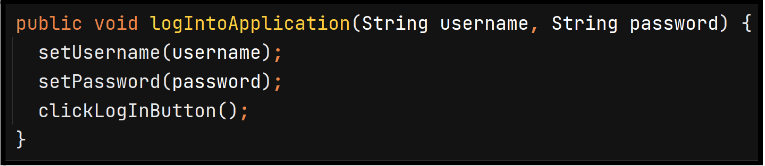
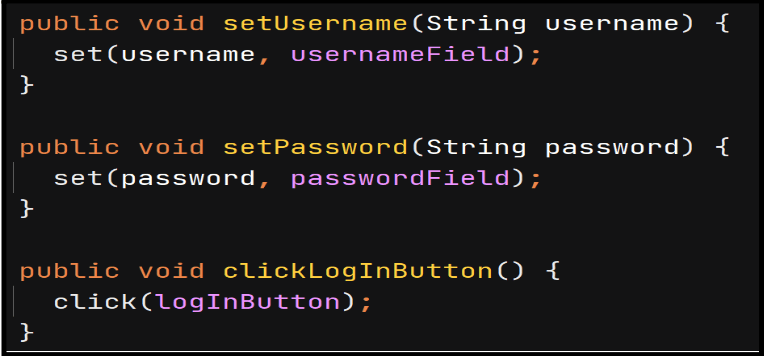
DRY Principle
DRY is an acronym for Don’t Repeat Yourself. If our project has the same code in diverse places, then we can consider creating a method/function for that code. Designing a method/function helps our code to become reusable and avoid repetition.
Some benefits to the DRY Principle are reducing the code base size and quicker to comprehend the code. Also, maintaining the code is much easier since a method/function is located in one place. After modifying the code, the change is reflected in all areas calling the method/function.
Refactor & Delete Unnecessary Code
Refactoring code is the operation of rebuilding code without changing its original functionality. It improves code with modest updates to make the design and implementation better. Refactoring also reduces the state of the code being complex.
Occasionally while enhancing a project, the old code is commented out rather than removed from the project. It is better to delete unnecessary code, so the source files do not clutter up. Sometimes the old code is ineffective if restored back to the project.
Write Good Comments
The purpose of a comment is to make our source code easier to understand while being ignored by compilers and interpreters. A good rule of thumb is for comments to explain ‘Why’ our code exists and not ‘What’ our code does.

If we write clean code, then the code should be self-explanatory to what it does. It explains why the code was written to shed light on its intention. An example of a relevant comment is explaining a 3rd Party API so you and your team have clarification. Here is an example of some irrelevant comments:
- Enter Username
- Enter Password
- Click Login Button
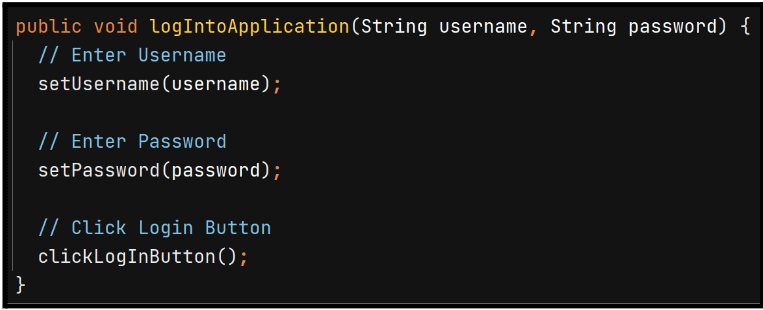
Recap
Writing clean code is critical because it grants communication with the next Test Automation/SDET Engineer. The main point for clean code is to write for the reader. It will be difficult to update and extend the project if the code is not clean. Therefore, we should think about our teammate who might support the code.
A few reasons for unpleasant code are requirement change, trying to finish fast, and the mindset of “it’s working now, but I will optimize it later”. Although an unpleasant code is subjective, if principles are violated, then that is a code smell sign. Code smell indicates a deeper problem with our source code.
The tips for clean code consists of using descriptive names, implementing one action for each method/function, DRY principle, refactoring the code, deleting unnecessary comments, and writing good comments.
Descriptive names are detailed, specific, and adhere to conventions. There are exceptions to known names recognized as acronyms, like mph. For example, we can optionally omit writing milesPerHour because mph is a recognizable acronym.
It’s a fundamental concept for each method/function to perform one action. If the same code has been implemented in multiple parts of the program, then we should create a method/function. The method/function is reusable and promotes the DRY principle so we can avoid repetition.
When it comes to refactoring our code, the code is rebuilt but does not change the initial functionality. It’s a way of improving our code to operate better. Unnecessary code is removed to prevent clutter in the existing code base. Comments are good when they explain ‘Why’ our code exists in the project.

Rex Jones
Rex Jones II has a passion for sharing knowledge about leadership and testing software. His background is development but enjoys testing applications.
Rex is an author, trainer, consultant, and former Board of Director for User Group: Dallas / Fort Worth Mercury User Group (DFWMUG) and member of User Group: Dallas / Fort Worth Quality Assurance Association (DFWQAA). In addition, he is a Certified Software Tester Engineer (CSTE) and has a Test Management Approach (TMap) certification.
Rex created a social network that demonstrate Programming and Test Automation videos. In addition to the social network, he has written multiple Programming / Automation books covering VBScript the programming language for QTP/UFT, Java, Python, Selenium WebDriver, Page Object Model, and TestNG.
![]()
![]()
![]()
Related Posts
 Top 10 QA Automation Tools In 2025
Top 10 QA Automation Tools In 2025
Top 10 QA Automation Tools In 2025
 FinancialForce Is Now Certinia – What Does This Mean Going Forward?
FinancialForce Is Now Certinia – What Does This Mean Going Forward?



